Introducing Contextual Retrieval
Source:
https://www.anthropic.com/news/contextual-retrieval
The Problem with Traditional Retrieval-Augmented Generation (RAG)
AI models often need background knowledge to be useful in specific contexts (e.g., customer support chatbots, legal analyst bots).
Retrieval-Augmented Generation (RAG) is used to enhance an AI model's knowledge by retrieving relevant information from a knowledge base and appending it to the user's prompt.
Traditional RAG solutions remove context when encoding information, leading to the system failing to retrieve the relevant information from the knowledge base.
Issues with Current Solutions
Traditional RAG systems split documents into smaller chunks for efficient retrieval, but this can lead to problems when individual chunks lost the context.
Example: a financial report where a chunk mentions revenue growth but doesn't specify the company or time period, making it difficult to retrieve the right information.
Introducing Contextual Retrieval
Contextual Retrieval solves this problem by prepending chunk-specific explanatory context to each chunk before embedding (Contextual Embeddings) and creating the BM25 index (Contextual BM25).
This added context helps the system understand the chunk's relevance to the query, improving retrieval accuracy.
Benefits of Contextual Retrieval
Reduces the number of failed retrievals by 49% (and by 67% when combined with reranking).
Directly translates to better performance in downstream tasks.
Can be easily deployed with Claude with a provided cookbook.
Implementing Contextual Retrieval
To avoid manual annotation, Claude is used to provide concise, chunk-specific context that explains the chunk using the context of the overall document.
A specific Claude prompt is used to generate context for each chunk, which is then prepended to the chunk before embedding and BM25 indexing.
Prompt caching can be used to reduce the costs of Contextual Retrieval by loading the document into the cache once and referencing it for each chunk.
Other implementation considerations include chunk boundaries, embedding model, custom contextualizer prompts, and the number of chunks.
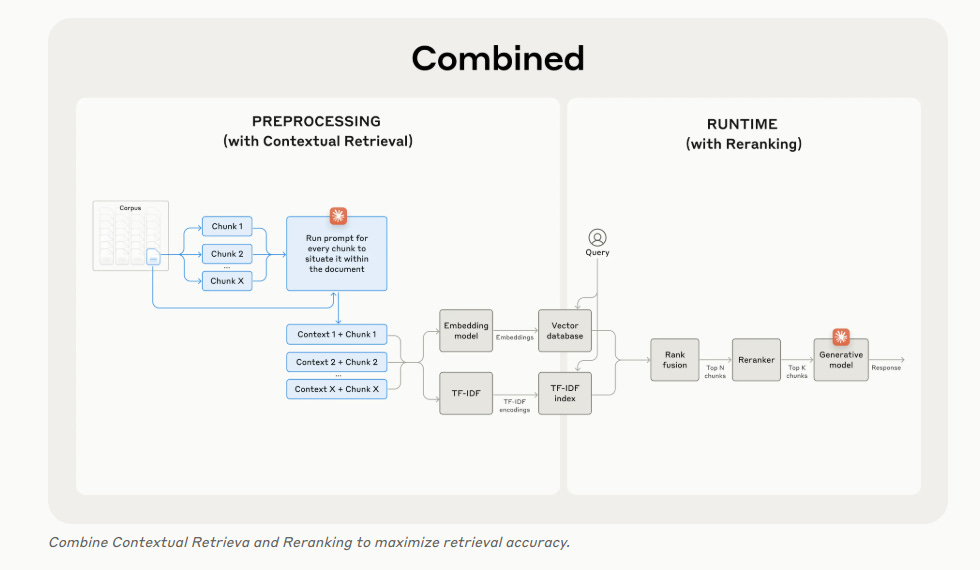
Further Boosting Performance with Reranking
Reranking can be combined with Contextual Retrieval to further improve performance, ensuring that only the most relevant chunks are passed to the model.
This reduces cost and latency because the model is processing less information.
By combining Contextual Retrieval and reranking, developers can achieve significant improvements in retrieval accuracy and overall AI model performance.